
Today’s topic is a slightly unusual one as it’s all technical authoring for maximum translation benefit, or more simply, writing for translation.
You might already be looking at me with a puzzled expression. Surely, translation happens AFTER you’ve written the text, not before or during?! Well, yes and no.
I’ve touched on this before in my blogs about reducing translation costs and understanding translation memory software, as well as the blog about optimising your content for translation.
Today I’d like to look at it in slightly more detail, as well as introducing a STAR Group tool that could just simplify your technical writing process.
Writing clearly and concisely
This should be an obvious one.
In any technical authoring task, your number one objective should be to write clearly and concisely. Keep your sentences short. Avoid jargon and overcomplicating your subject.
This does not change when you are writing your document for translation.
It just becomes more important.
Looking at potential fuzzy match percentages
I discuss fuzzy matches a lot in these posts, and I always try to avoid jargon. However, I appreciate that the whole concept of a fuzzy match might feel like an alien language.
Today, I’m going to try and give you an example.
Translation memory software works on the basis of analysing similarity between two units of language; usually a sentence.
Using a fuzzy logic algorithm, it breaks down the sentence into its component parts, i.e. words, punctuation marks and numbers.
It looks at each one of these component parts, checks whether it has moved or disappeared from the sentence and combines the results from each component analysis to create a fuzzy match percentage.
That’s about all the explanation I can give you. No, seriously, don’t ask me any further questions on this. Computer science is not my strong point! Plus, every company uses different weightings in the algorithm so they will all get slightly different numbers.
So let’s look at an example.

Examples:
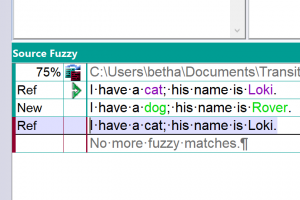
I have a cat; his name is Loki.
I have a dog; his name is Rover.
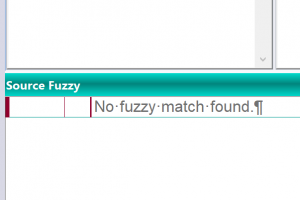
My dog’s name is Rover.
If we consider the first sentence to be already translated, what do the two examples tell us about potential fuzzy matches?
Factually, both subsequent sentences have the same meaning. You possess a dog; you call him Rover.
There are two changes between sentence 1 and sentences 2/3:
- Dog not cat
- Rover not Loki
Comparison of sentence 1 and 2: 75% (classed as a fuzzy match)
Comparison of sentence 1 and 3: Less than 30% match (this will be classed as new words)
Every agency will have a different breakdown of costs between fuzzy matches and new words, but the principle is the same. New words cost more.
If your entire document contains similar issues, costs will be significantly higher than they need to be.
Avoiding errors
We’re all aware that texts that contain errors are more difficult for the reader. Either grammatical errors in long, tangled sentences, or perhaps a sentence that is littered with typing errors.
Both of these also cause issues for the translator. Potentially it is an issue that is amplified by the fact that they are not native speakers of your language and might find it harder to untangle or decipher the mistakes.
It might take the translator longer to complete your translation project and they may be less willing to work on your texts in the future. As well as there being a risk that they will misunderstand part of your text.
So, how does this affect your costs?
I’ve not come across any agency that imposes cost penalties for texts that contain multiple errors, though they may suggest carrying out an additional proofreading step before translation.
The costs come from misunderstandings that lead to further proofreading steps and incur additional costs to correct errors.
Another concern is for subsequent projects where errors have been corrected. Instead of being able to reuse material as pretranslation, your latest project will be considered as fuzzy matches only. This will add a sizeable percentage increase to your technical translation quotation.
Introducing MindReader
This blog is not really about selling, so I’ll keep this section brief. Even with the best of intentions, it can be difficult to write consistently. It’s more likely that consistency issues will only be found at a proofreading stage or that they might slip through the net completely.
For this reason, the STAR Group has developed authoring tools to help; MindReader and MindReader for Outlook.
Like any tool from STAR, the principle is that you only work on content that is new. Think of it a little bit like autocomplete on your mobile. Just start typing your sentence, and the tool will provide suggestions from elsewhere in your document.
If you want to reuse them, you can. If you don’t, you can ignore them.
It can help with consistency in your technical writing, which will improve clarity as well as bringing down potential translation costs.
If it sounds like something you could be interested in, contact one of our team today.
I hope this blog has been useful in giving you some tips for improving your technical writing and lowering your translation costs.
If you want any further information about this, or to discuss a potential project with one of the team, please do not hesitate to get in touch.


